....
Kafka Overview
Kafka features that are relevant to addressing our specific use case.
Value proposition
Scalability: Distributed system that scales linearly. A production cluster can start at 3 machines and expand as needed.
Performance: High throughput for producers and consumers.
Durability: Replication over three machines allow two machines to fail without losing data. Persists messages on disk.
Reliability: Replicated data. Supports multiple consumers with rebalancing in case of failure.
Use cases
-
Message processing with built-in fault-tolerence
-
Message Bus, Message Queue
-
Event sourcing, CQRS and Stream Processing
-
Distributed commit Log

Components
- Kafka Broker
-
A single Kafka server is called a broker. Kafka brokers are designed to operate as part of a cluster.
- Kafka Cluster
-
A collection of Brokers, one of them is the leader.
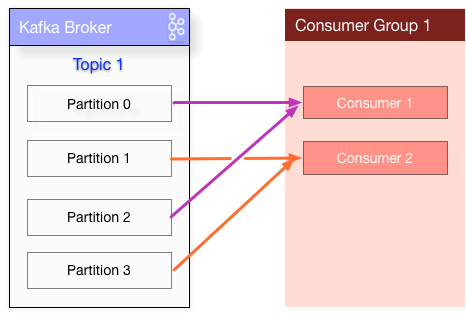
- Topics and Partitions
-
Messages are categorized into topics and are like a database table or file folder. Topics are broken into a number of partitions.
Brokers and Clusters
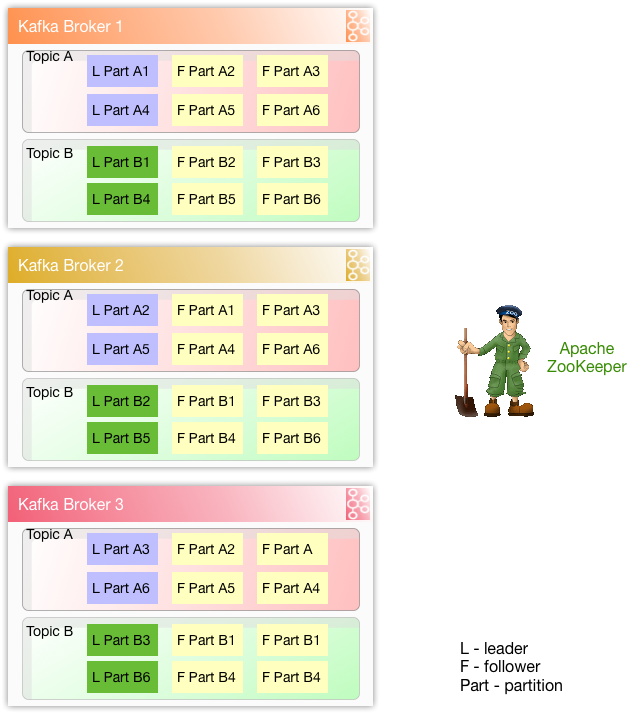
The replication mechanisms within the Kafka clusters are designed only to work within a single cluster and not between multiple clusters.
|
Note
|
Topics and Partitions would need to be designed for migrating from JMS. Topics can be consumed with Regular Expressions. Naming convention is similar to Java package naming convention. |
Multi-Datacenter Replication
Replication of events between datacenters can be done with
-
open source MirrorMaker
-
licensed Confluence Enterprise Replicator.
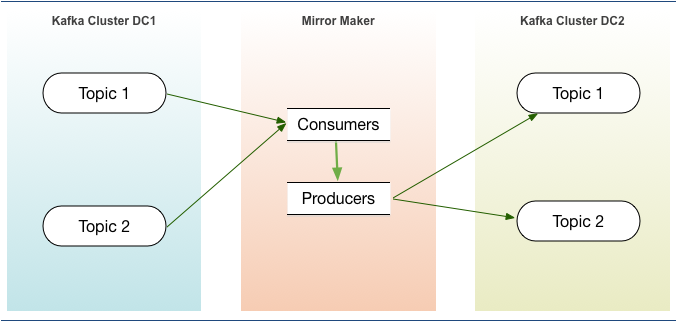
-
An Active-passive configuration can be used for Disaster recovery. The above figure shows such an implementation with MirrorMaker.
-
A geo-localized deployment would need 2 way replication, with 2 clusters in Active-active configuration. While MirrorMaker can be used for this, it is best handled by Confluent Enterprise Replicator.
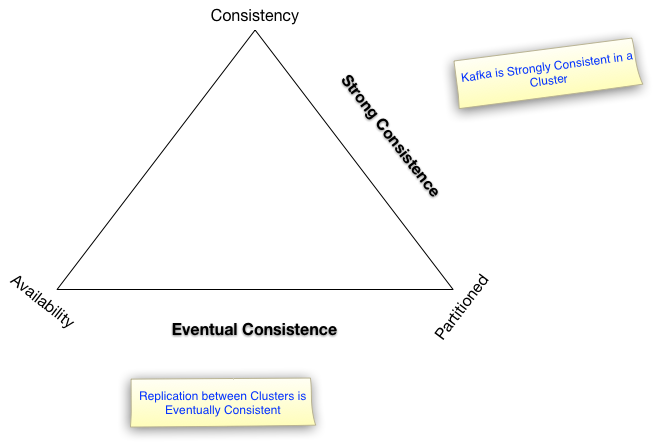
CAP Theorem
Kafka Producer
Messages are the data that brokers store in the partitions of a topic. They are persisted on disk and replicated within the cluster to prevent data loss.
Messages are in partitions until deleted when TTL occurs or after compaction.
Offsets are message positions in a topic.
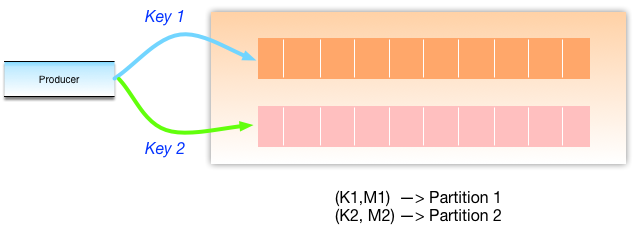
JMS message is metadata and a payload body. In Kafka the message is a key-value pair, with value being the message payload.
Key is used for partitioning. A business specific key ensures related messages in the same partition.
Ordering of messages is within a partition and not between partitions in a topic.
A retry mechanism is used when adding a message to a broker. A configuration needs to be set for ensuring that no additional messages are sent during a retry.
Kafka Consumer
Message are consumed through polling only. This is unlike JMS API, which can watch for messages.
Once the consumer subscribes to topics, the poll loop handles all details of coordination, partition rebalances, heartbeats, and data fetching
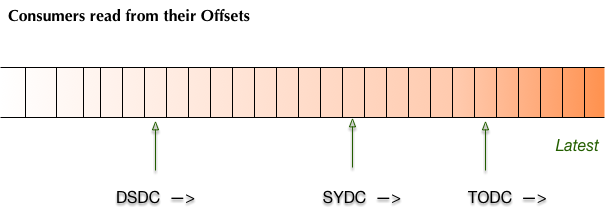
Commit of offsets can be controlled with methods commitSync() and commitAsync()
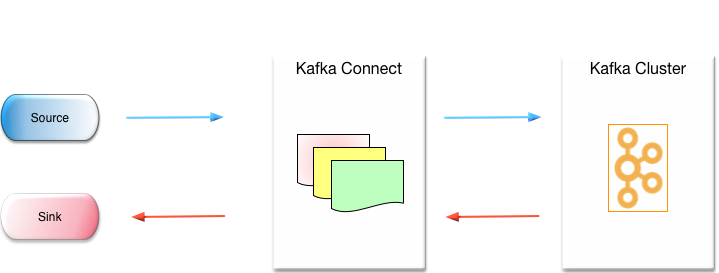
Kafka Connect
Kafka Connect is an open source framework and is a part of Apache Kafka.
Connectors are availablefor various sources and targets.
https://www.confluent.io/hub/
A licensed connector is available for IBM MQ/JMS/Active MQ.
Data Encoding
Kafka messages are byte arrays.
JSON and the binary Apache Avro are commonly used for serialization.
API provides an interface for custom serializer/deserializer.
Compression can optionally be enabled. Snappy, gzip and lz4 are supported.
XML serde’s are avaialble for Kafka. JSON with Jackson API may be preferable.
JMS Kafka Comparison
Kafka is a distributed platform and some of the features like, Scalability, Durability, Reliability and Performance follow from it.
| JMS | Kafka | Comments |
|---|---|---|
push |
pull |
Push vs Pull discussion http://kafka.apache.org/documentation.html#theconsumer |
point-to-point, pub-sub |
pub-sub |
for Kafka point-to-point would be a special case with one partition and a consumer and producer |
payload header and Body |
key value pairs |
|
multiple serialize/deserialize options |
||
persistence on disk |
Circular Buffer with TTL/Size |
|
priority queues |
special case where message key is fixed |
|
Filtering with JMS Provider |
KStreams can be used for this |
|
Dead Letter Queue |
Service implementation |
|
implementation specific |
Fault tolerent cluster |
|
2 million writes/sec |
||
Commodity hardware without RAID |